Deine KI-generierten Tests lügen dich an

Meine Test-Suite war grün.
393 Test-Dateien. Python Unit Tests, TypeScript/Vitest Frontend Tests, Hypothesis Property Tests, Playwright E2E Specs. Alle generiert im Spec Mode mit AWS Kiro, im Rahmen des Aufbaus eines vollständigen SaaS-Produkts: alleine, über 52 Tage, 292.000+ Netto-Codezeilen.
Alles grün. Ich war zufrieden.
Dann setzte sich ein Kollege mit mir hin und fing an, sich einige Tests genauer anzuschauen.
Er sagte zunächst nicht viel. Er zeigte einfach.
Ich hatte zuvor über Spec-Driven Development geschrieben: wie Kiro einen dazu zwingt, nachzudenken, bevor auch nur eine Zeile Code generiert wird, und wie die Disziplin hinter Specs und Steering Files das ist, was wartbaren Enterprise-Code von den architektonischen Sackgassen des Vibe Codings unterscheidet. Daran glaube ich nach wie vor. Aber ich war so sehr auf Feature-Delivery fokussiert, auf Specs und Architektur und die schiere Geschwindigkeit von dem, was eine Einzelperson mit agentic AI aufbauen kann, dass ich etwas übersehen hatte, das direkt vor mir lag.
Die Tests sahen korrekt aus. Sie liefen durch. Sie bestanden. Aber viele von ihnen testeten schlicht nichts.
Sieben Anti-Patterns, die sich durch jede Schicht ziehen
Nach diesem Gespräch fing ich an, tiefer zu graben. Was ich fand, war systematisch, nicht zufällig. KI-generierte Tests scheitern in vorhersehbaren Mustern. Dieselben Anti-Patterns tauchen immer wieder auf, über alle Schichten hinweg: Infrastruktur, Backend, Frontend.
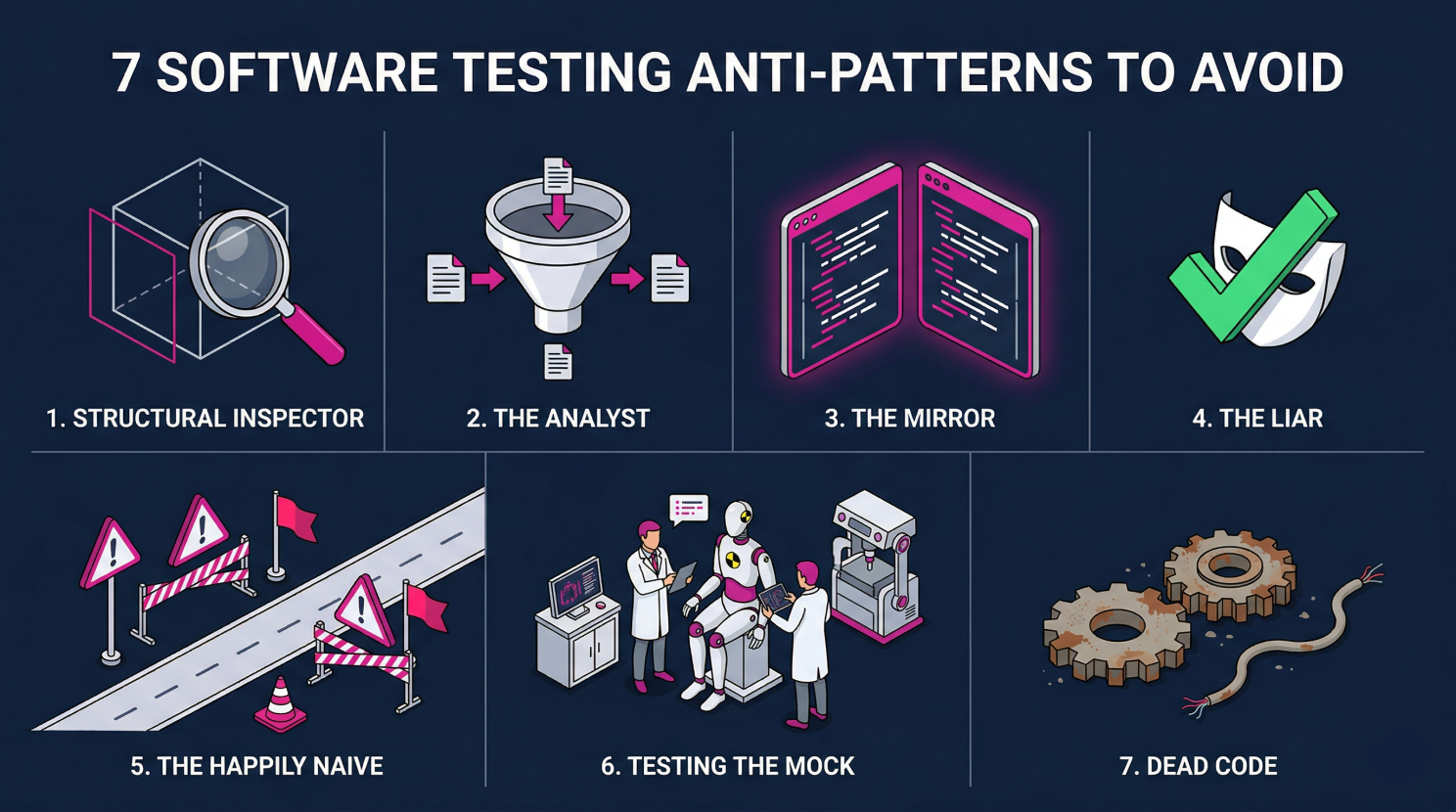
Hier ist, was ich in der Codebase dokumentiert habe:
The Structural Inspector ist das häufigste Muster. Der Test prüft, ob ein Objekt eine bestimmte Eigenschaft oder Struktur hat, nicht ob es sich korrekt verhält. Er inspiziert, verifiziert aber nicht. Gefunden in 30+ Dateien, dominant in der Infrastruktur-Schicht.
The Analyst prüft Outputs, die direkt in den Mock-Input hardcoded wurden. Eine Tautologie im Testgewand: "Gegeben Input X, Output ist X." Gefunden ca. 35 Mal.
The Mirror ist ein tautologischer Test, der im Wesentlichen die Implementierung gegen sich selbst prüft. Der Test besteht, weil er das kopiert, was die Funktion tut, nicht das, was sie tun sollte. Ca. 20 Instanzen.
The Liar ist auch bekannt als der Evergreen Test. Er besteht, egal was der Code tut. Die Assertion ist entweder inhaltsleer oder immer wahr. Ca. 18 Instanzen.
The Happily Naive deckt nur den Happy Path ab, ohne Edge Cases, ohne Grenzwerte, ohne Fehlerszenarien. Ca. 18 Instanzen.
Testing the Mock validiert, dass der Mock das zurückgibt, wofür er konfiguriert wurde. Der eigentliche Produktionscode wird nie ausgeführt. Ca. 15 Instanzen.
Dead Code bezeichnet Test-Dateien, die interne Hilfsfunktionen testen, die nie exponiert werden und kein produktionsrelevantes Verhalten haben. Ca. 8 Dateien.
Und dann gibt es noch eine universelle Qualitätsverletzung, die sich durch alle Schichten zieht: Keine einzige Python-Test-Datei verwendet # Arrange / # Act / # Assert Struktur-Kommentare. Keine einzige. Über ca. 100 Python-Dateien hinweg.
Das ist keine Stilfrage. Es ist ein Signal. Wenn keine kognitive Struktur die Trennung von Setup, Ausführung und Assertion erzwingt, kollabieren die Tests ineinander und werden zu Rauschen.
Was ich zuerst versucht habe und warum es nicht funktioniert hat
Mein erster Instinkt war, einen Prompt zu schreiben. Codebase analysieren, schwache Tests identifizieren, einen Report ausgeben. Er lief durch. Er produzierte Output. Aber er war inkonsistent, unvollständig, und ich hatte keine verlässliche Methode, die Ergebnisse zu operationalisieren.
Das Problem mit einem Ad-hoc-Prompt ist, dass er nicht weiß, wie gut aussieht. Er braucht ein Framework: eine Taxonomie dessen, was als Problem gilt, warum es wichtig ist und wie die Behebung priorisiert werden soll.
Also habe ich eines gebaut.
Ein Kiro Skill für das Test-Review
Wer mit Kiro gearbeitet hat weiß, dass Skills eines der am meisten unterschätzten Features sind. Sie erlauben es, wiederverwendbare, meinungsstarke Workflows zu definieren, die Kiro konsistent anwendet: über Tasks, über Sessions, über die gesamte Codebase.
Ich habe einen Kiro Skill speziell für das Review von KI-generierten Tests gebaut. Er operationalisiert die sieben Anti-Patterns oben, wendet sie systematisch auf jede Test-Datei an und produziert strukturierte Findings.
Der Workflow läuft in drei Schritten. Zuerst führe ich den Review-Skill aus. Er analysiert alle Test-Dateien und identifiziert jede Instanz der Anti-Patterns. Er markiert sie nicht nur, sondern erklärt, warum jede problematisch ist und wie ein korrekter Test aussehen würde.
Dann strukturiere ich die Findings. Ein Prompt sortiert sie nach Priorität in Markdown-Dateien: was gelöscht werden soll, was neu geschrieben werden muss, was komplett fehlt, welche Strukturverletzungen behoben werden müssen.
Schließlich triggere ich den Implementierungs-Task. Mit den strukturierten und priorisierten Findings erstelle ich einen Task in Kiro (direkt, ohne Spec Mode, denn das Design und die Requirements kommen bereits aus dem Skill-Output). Kiro arbeitet die Remediation-Liste systematisch ab.
Das hat auch bei längeren Durchläufen gut funktioniert. Bei größerem Task-Scope lasse ich es einfach laufen. Das ist eines der Dinge, die sich in der Arbeitsweise ändern, wenn man dem agentischen Loop vertraut: Man sitzt nicht daneben und schaut zu. Man setzt den Task, geht weg und kommt zu einem fertigen Merge Request zurück.
Was die Bereinigung verändert hat
Nach dem vollständigen Workflow-Durchlauf in meinem Projekt:
- 6 Test-Dateien vollständig gelöscht (sie testeten schlicht nichts Reales)
- ca. 35 einzelne Tests gelöscht (Rauschen, kein Signal)
- ca. 92 Property/Hypothesis Tests neu geschrieben (55 Python, 37 TypeScript; Struktur war da, Assertions waren falsch)
- ca. 60 neue Tests hinzugefügt (Abdeckung, die behauptet wurde, aber nicht existierte)
- ca. 140 Anti-Pattern-Instanzen behoben über alle Schichten
Das ist ein signifikanter Teil von 393 Test-Dateien. Die Suite läuft danach immer noch grün. Aber jetzt bedeutet das auch etwas.
Warum "sieht korrekt aus" nicht "ist korrekt" heißt
KI-Tools im Spec Mode generieren Tests, die korrekt aussehen. Die Syntax stimmt, die Struktur ist erkennbar, die CI bleibt grün. Aber "sieht korrekt aus" und "ist korrekt" driften still auseinander, und diese Divergenz wächst mit jedem Feature, das man auf ein Test-Fundament aufbaut, dem man zu vertrauen glaubt.
Das ist kein Grund, KI für die Test-Generierung aufzugeben. Die Geschwindigkeit ist real. Die Fähigkeit ist real. Aber es bedeutet, dass man eine Review-Schicht braucht: idealerweise automatisiert, konsistent und Teil des Workflows, kein Afterthought.
Der Skill ist Open Source. Herunterladen, in Kiro installieren, gegen die eigene Codebase laufen lassen:
https://github.com/obue/ai-test-review
Wer mit Kiro oder einem anderen agentischen AI-Tool arbeitet und Tests in größerem Umfang generiert, dem empfehle ich, diesen Skill in den Workflow zu integrieren, bevor der nächste grüne Build einem zu viel Sicherheit gibt.
Welche Erfahrungen habt ihr mit der Qualität KI-generierter Tests gemacht? Habt ihr eigene Muster gefunden oder eigene Lösungen entwickelt? Mich interessiert, was ihr in der Praxis seht.