Your AI-Generated Tests Are Lying to You

My test suite was green.
393 test files. Python unit tests, TypeScript/Vitest frontend tests, Hypothesis property tests, Playwright E2E specs. All generated in Spec Mode with AWS Kiro, as part of building a complete SaaS product: alone, over 52 days, 292,000+ net lines of code.
All green. I was satisfied.
Then a colleague sat down with me and started looking more closely at some of the tests.
He didn't say much at first. He just showed me.
I had written before about Spec-Driven Development: how Kiro forces you to think before a single line of code gets generated, and how the discipline behind specs and steering files is what separates maintainable enterprise code from the architectural dead ends of vibe coding. I still believe that. But I had been so focused on feature delivery, on specs and architecture and the sheer speed of what a single person can build with agentic AI, that I had missed something sitting right in front of me.
The tests looked correct. They ran. They passed. But many of them were simply testing nothing.
Seven Anti-Patterns That Repeat Across Every Layer
After that conversation I started digging deeper. What I found was systematic, not random. AI-generated tests fail in predictable patterns. The same anti-patterns appear repeatedly, across every layer: infrastructure, backend, frontend.
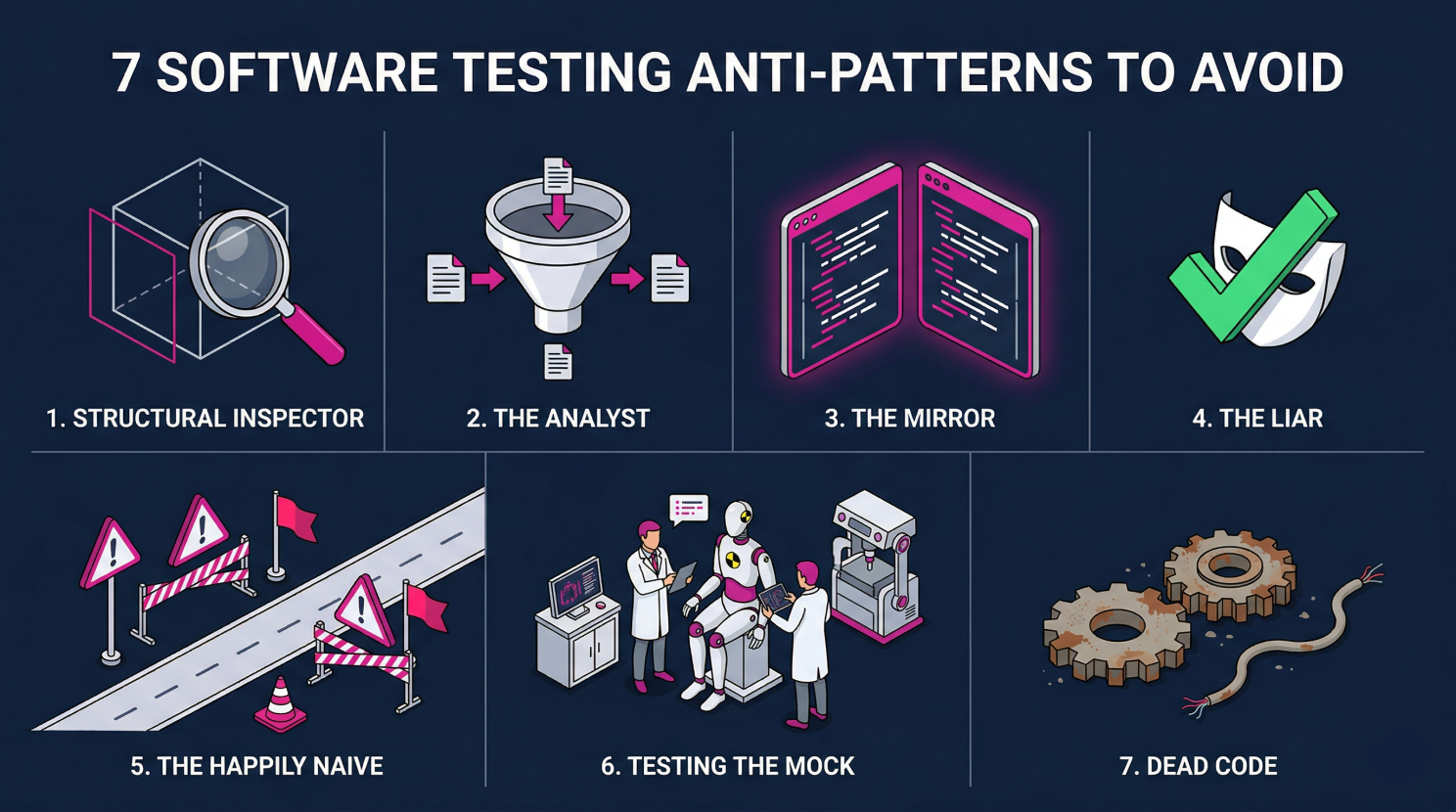
Here is what I documented in the codebase:
The Structural Inspector is the most common pattern. The test checks whether an object has a certain property or structure, not whether it behaves correctly. It inspects but does not verify. Found in 30+ files, dominant in the infrastructure layer.
The Analyst checks outputs that were hardcoded directly into the mock input. A tautology dressed as a test: "Given input X, output is X." Found approximately 35 times.
The Mirror is a tautological test that essentially checks the implementation against itself. The test passes because it copies what the function does, not what it should do. Approximately 20 instances.
The Liar is also known as the Evergreen Test. It passes regardless of what the code does. The assertion is either vacuous or always true. Approximately 18 instances.
The Happily Naive covers only the happy path, with no edge cases, no boundary values, no error scenarios. Approximately 18 instances.
Testing the Mock validates that the mock returns what it was configured to return. The actual production code is never executed. Approximately 15 instances.
Dead Code refers to test files that test internal helper functions which are never exposed and have no production-relevant behavior. Approximately 8 files.
And then there is a universal quality violation running through every layer: not a single Python test file uses # Arrange / # Act / # Assert structure comments. Not one. Across approximately 100 Python files.
That is not a style question. It is a signal. When no cognitive structure enforces the separation of setup, execution, and assertion, tests collapse into each other and become noise.
What I Tried First and Why It Did Not Work
My first instinct was to write a prompt. Analyze the codebase, identify weak tests, produce a report. It ran. It produced output. But it was inconsistent, incomplete, and I had no reliable way to operationalize the results.
The problem with an ad-hoc prompt is that it does not know what good looks like. It needs a framework: a taxonomy of what counts as a problem, why it matters, and how remediation should be prioritized.
So I built one.
A Kiro Skill for Test Review
Anyone who has worked with Kiro knows that Skills are one of its most underrated features. They let you define reusable, opinionated workflows that Kiro applies consistently: across tasks, across sessions, across the entire codebase.
I built a Kiro Skill specifically for reviewing AI-generated tests. It operationalizes the seven anti-patterns above, applies them systematically to every test file, and produces structured findings.
The workflow runs in three steps. First I run the review skill. It analyzes all test files and identifies every instance of the anti-patterns. It does not just flag them. It explains why each is problematic and what a correct test would look like.
Then I structure the findings. A prompt sorts all findings by priority into markdown files: what should be deleted, what needs to be rewritten, what is completely missing, which structural violations need to be fixed.
Finally I trigger the implementation task. With the structured and prioritized findings, I create a task in Kiro (directly, without Spec Mode, because the design and requirements already come from the skill output). Kiro works through the remediation list systematically.
This worked well even for longer runs. With larger task scope I simply let it run. That is one of the things that changes in how you work when you trust the agentic loop: you do not sit next to it and watch. You set the task, walk away, and come back to a finished merge request.
What the Cleanup Changed
After running the full workflow in my project:
- 6 test files deleted entirely (they were simply testing nothing real)
- approximately 35 individual tests deleted (noise, no signal)
- approximately 92 Property/Hypothesis tests rewritten (55 Python, 37 TypeScript; structure was there, assertions were wrong)
- approximately 60 new tests added (coverage that was claimed but did not exist)
- approximately 140 anti-pattern instances fixed across all layers
That is a significant portion of 393 test files. The suite still runs green after all of this. But now that actually means something.
Why "Looks Correct" Is Not "Is Correct"
AI tools in Spec Mode generate tests that look correct. The syntax is right, the structure is recognizable, CI stays green. But "looks correct" and "is correct" drift silently apart, and that divergence grows with every feature you build on top of a test foundation you think you can trust.
That is not a reason to stop using AI for test generation. The speed is real. The capability is real. But it means you need a review layer: ideally automated, consistent, and part of the workflow, not an afterthought.
The skill is open source. Download it, install it in Kiro, run it against your own codebase:
https://github.com/obue/ai-test-review
If you are working with Kiro or any other agentic AI tool and generating tests at scale, I recommend integrating this skill into your workflow before the next green build gives you more confidence than it should.
What has your experience been with the quality of AI-generated tests? Have you found your own patterns or developed your own solutions? I am curious what you are seeing in practice.