Kiro vs. Vibe Coding: Why Spec-Driven Development Is the Key to Sustainable Enterprise Code
Two things I value most about diving: absolute calm and flawless precision. That precision is exactly what pure vibe coding with generative AI has always lacked for me, above all when it comes to secure enterprise architectures.
Last Tuesday, 24 February, I was in Frankfurt presenting AWS Kiro to a group of colleagues. The looks on their faces said everything.
That was the moment I knew I had to write this down.
The Illusion of Vibe Coding and the Enterprise Reality
"Just coding away and blindly trusting generative AI may get us to our goal quickly in the short term. But the code that results is often an unmaintainable nightmare that ends up in an architectural dead end."
This is not theory. It is the finding after weeks of intensive work with generative AI in an enterprise context.
Vibe coding (the principle of having an AI generate code through natural-language prompts without fixed specifications) works for prototypes, demos, and scripts. The path to running code is short. The feedback loop is fast. You see results.
But enterprise code carries different requirements: security, auditability, maintainability, clear responsibilities between components. A compliance tool for cloud infrastructure cannot afford to stand on an architectural patchwork. Building with generative AI and no structure produces code that works today and that nobody understands tomorrow, let alone modifies.
The counterpart is Spec-Driven Development. And that is exactly what makes AWS Kiro a different kind of tool.
The Architecture: A Real Stress Test (3-Tier Monorepo)
I have not been building toy projects. The product is an AWS Compliance Snapshot Tool, a SaaS product for cloud security compliance. Built alone, without a development team, starting 27 January 2026.
The architecture is a 3-tier monorepo:
- Infrastructure: Terraform with 18 modules
- Backend: Python AWS Lambda functions (10 in Phase 1, 19 total planned)
- Frontend: Next.js application
- CI/CD: GitLab pipeline with 1,167 lines
This is not a prototype. These are real layers, real dependencies, real security requirements. Terraform modules need to be coordinated with one another. Lambda functions need clean separation. The pipeline needs to be deterministic.
This is precisely the complexity at which vibe coding breaks down. The larger the architecture, the faster an uncontrolled agent loses the thread. It hallucinates dependencies, overwrites configuration, breaks interfaces. The correctness of a single prompt's output says nothing about the structural coherence of the overall architecture.
This is the stress test I put Kiro through: can an AI agent develop a production architecture of this complexity over weeks, consistently and correctly? The answer depends almost entirely on the method, not the model.
The Paradigm Shift: Spec-Driven Development Explained
"Kiro forces you to think before a single line of code gets written."
That is the central difference. And it runs deep.
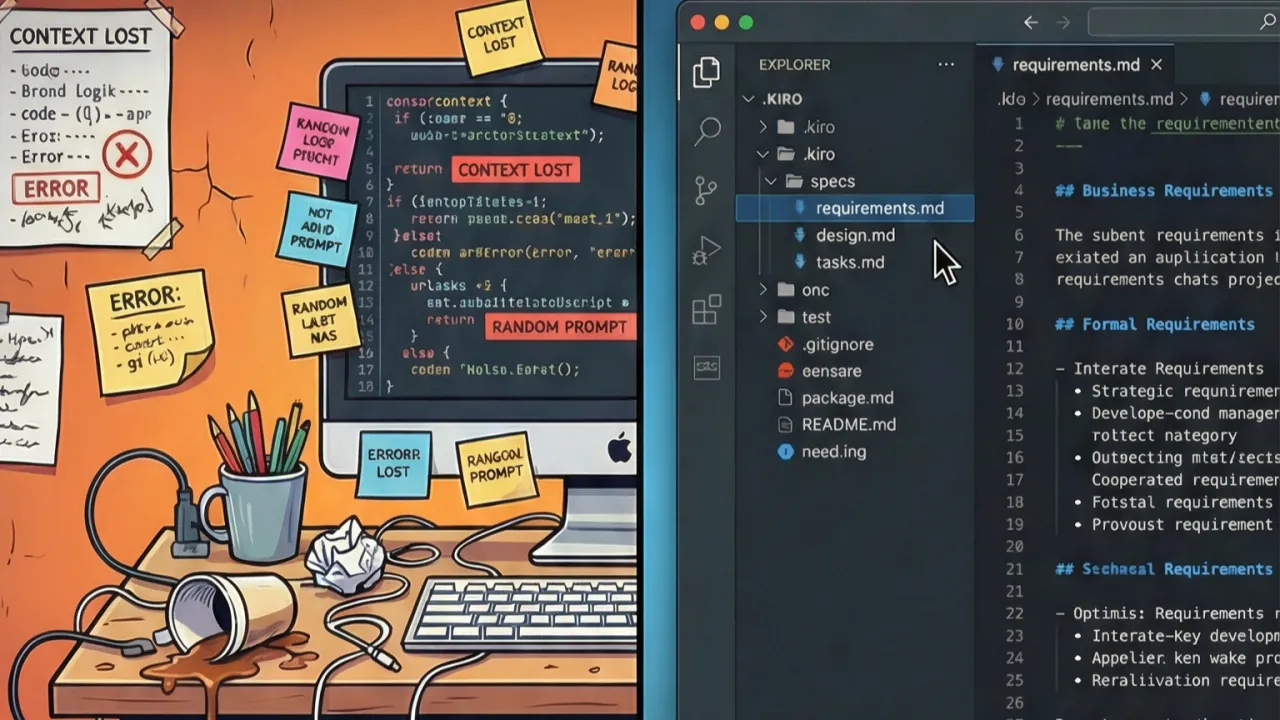
In Kiro's Spec Mode, you create a structured specification under .kiro/specs/ before every feature. Each spec consists of three files: requirements.md, design.md, and tasks.md. Requirements are written in EARS notation: "WHEN [condition] THE SYSTEM SHALL [behavior]." This is not an academic exercise. It is the craft that cuts out ambiguity before it becomes code.
The design document describes the technical implementation at the component level: which data structures, which interfaces, which dependencies. The tasks file breaks the design into atomic, executable units of work.
The result: the agent has precisely the right context knowledge for each task.
"When the agent executes a specific task, it goes straight to the corresponding design. It knows exactly what it needs to do, without having to load the entire project context into memory."
This is architecturally elegant. Large codebases have large context-window problems. Loading the agent with the entire project context is a fight against drift, hallucinations, and inconsistent decisions. Encapsulating context per feature keeps you in control. The spec is the boundary. The agent works with precision within that boundary.
I created 33 specs in the first four weeks. Each one is a documented decision space that stays traceable long after the agent has moved on to the next feature.
Long-Term Memory and Automation: Steering, Skills & Hooks
Specs solve the feature-level problem. But keeping a project consistent over weeks takes more than feature specifications. It needs persistent project knowledge.
Kiro addresses this with Steering Files under .kiro/steering/. Mine are three core documents: product.md (what the product is, which decisions were made and why), tech.md (technology stack, conventions, prohibitions), and structure.md (how the repository is organized, which layer belongs where). These files load automatically at the start of every session. The agent does not forget any decision that has been documented.
Beyond that there are Skills: modular instruction packages for recurring tasks. A skill for creating Lambda functions. One for writing Terraform modules. One for test generation. The skill defines what the output should look like. The agent executes it to that standard, consistently.
Hooks are event-driven automations: "When X, then Y." When a new file is created, run this check. When a task completes, write the changelog. These triggers run in the background without me manually initiating every step.
The combination of these three mechanisms makes Autopilot Mode possible:
"There were times when I fully pre-specified a massive task, clicked 'Go', and went to sleep. The agent worked autonomously for two and a half hours."
That is not a marketing promise. That is the normal workflow after four weeks with Kiro. The context is clean. The steering files are complete. The scope is defined in the spec. The agent does not need a babysitter.
More material on best practices for working with these mechanisms is available in this repository: github.com/awsdataarchitect/kiro-best-practices

Transparency Through Hard Data: Git History After 4 Weeks
After 19 active working days (Phase 1, 27 January to 19 February 2026), the git history looks like this:
- 175,000+ net lines of code
- 305 commits
- 16.1 commits per day on average
- 60+ frontend components
- 143 generated test files
- approximately 80% test coverage
- 33 Kiro specs
These numbers do not interest me as a performance statement. They interest me as validation of the method. 305 commits over 19 days means: progress is granular, documented, reversible. 33 specs means: each of those commit series has a documented decision space behind it. 143 test files means: the code did not just get written, it got tested.
That is the difference between vibe coding and spec-driven development, in numbers.
Quality Assurance: Property-based Tests
80% test coverage alone says little. What matters is what the tests are testing.
For the backend and infrastructure I use property-based tests. Instead of fixed inputs, you define properties that the code must satisfy for every valid input. The test system generates hundreds of test cases automatically and attempts to disprove the property. This method finds edge cases that example-based tests miss by design.
The Kiro agent generates these tests from the EARS requirements in the specs. Because the requirements are precise, the tests can be precise. The specification is the foundation of test quality.
The 33 specs also produce a test plan that is not added after the fact. It is part of the feature specification from the start. Tests are not rework; they are part of the design.
143 test files for 19 working days means: an average of more than 7 new test files per day. That is not a rhythm achievable by hand. It is the product of a method that treats quality assurance as the first step, not the last.
The Cognitive Reality: A Completely Different Developer Day
What changed is not the speed of code output. It is my working day.
I am no longer a code writer. I am an "Intent Steerer" and "Code Auditor." I describe with precision what the system should do. I verify whether the agent has implemented that correctly. And I make architectural decisions for which my 10 AWS certifications and my background as a Cloud Security Architect are what matter, not my ability to type Python.
That sounds like less work. It is more.
A day as Intent Steerer and Code Auditor is cognitively more demanding than a day as a developer. You read more code than you would ever write yourself. You make more decisions per hour. You need to understand and evaluate every output from the agent before you merge it. A green build is not a free pass.
This is the mental shift that many people underestimate when talking about AI-assisted coding. The model writes the code. But someone needs to understand the code. And that someone needs to understand the code at a level that matches the responsibility they carry for it. Code they did not formulate line by line.
"We are not only building faster, but more securely and with better maintainability."
But that only holds true when the person steering the intent knows what secure and maintainable means. The AI can follow conventions. It understands the difference between a secure architecture and a merely complicated one only when that knowledge has been provided to it through steering files, specs, and skills.
Are your teams already using agentic AI? How do you deal with the massively increased cognitive load of constant code reviewing? And do you believe that "spec-driven" will completely replace "vibe coding" in the enterprise sector?